Иногда я открываю окно торрент-клиента и просто смотрю, как он раздаёт файлы… Это завораживает даже больше, чем дефрагментация или гейзеры и вулканы в трёхлитровой банке с домашним квасом. Ведь я помогаю множеству незнакомых мне людей качать нужные им файлы. Мой домашний компьютер — маленький сервер, ресурсами которого я делюсь со всем интернетом. Наверное, похожие чувства побуждают тысячи добровольцев по всему миру участвовать в проектах вроде folding@home.
Ни один файловый сервер не справился бы с тем объёмом раздачи, который обеспечивают миллионы маленьких компьютеров по всему миру, используя лишь небольшую часть своих ресурсов. Вот если бы я мог так же легко поделиться ресурсами с любым понравившимся мне сайтом! Если бы затраты на хостинг при росте аудитории росли не линейно, а логарифмически, за счёт «добровольного ботнета» из компьютеров посетителей. Насколько меньше рекламы я бы увидел? Сколько интересных стартапов избавились бы от головной боли по поводу масштабирования? Сколько некоммерческих проектов могли бы перестать зависеть от благосклонности меценатов? И насколько труднее было бы кибергопникам или спецслужбам DDoS-ить такой сайт!
Цена вопроса
Сейчас в мире больше полутора миллиардов компьютеров, подключённых к интернет. Из них около 500 миллионов имеют широкополосное подключение. Если предположить, что средний возраст домашнего компьютера — около двух лет, то можно считать, что у него простенький двухъядерный процессор, 1 -2 гигабайта памяти и винт на 500 гигабайт. Для определённости предположим также, что средняя скорость широкополосного соединения — 10 мегабит/сек.
Много это или мало? Что будет, если нам удастся добраться до этой скрытой массы ресурсов? Прикинем на глазок. Допустим, что если оставлять эти компьютеры включёнными круглосуточно, то не меньше трёх четвертей их ресурсов будут простаивать (это более, чем осторожная оценка, в Википедии фигурирует средняя нагрузка на сервер в 18%!). Если же загрузить компьютер как следует, то вырастет энергопотребление, скажем на 70 ватт в час на один компьютер, или на 50 киловатт/час в месяц. При средней цене электричества в мире около 10 центов за киловатт/час — это $5 в месяц. Плюс возникает вопрос повышенного износа. Вопрос довольно спорный, большинство комплектующих серьёзных производителей безнадёжно устаревают морально гораздо раньше, чем ломаются, кроме того, есть мнение, что постоянные включения-выключения и связанные с ними нагрев-остывание и другие переходные процессы приводят к выработке ресурса быстрее, чем круглосуточная работа. Тем не менее, включим в расчёт лишние 150 долларов на ремонт, размазанные, скажем, на 4 года эксплуатации. Это ещё чуть больше 3 долларов в месяц. Итого — 8 долларов в месяц или 100 долларов в год дополнительных расходов. С другой стороны, если три четверти ресурсов, за которые мы уже заплатили в момент покупки компьютера, сейчас простаивает, то при средней цене системника в 500 долларов — 375 мы выбрасываем на свалку. Если учесть, что эти 375 мы потратили сразу, то при распределении этой суммы на 4 года эксплуатации, получаем как раз те же 100 долларов в год. Ещё, пожалуй, стоит упомянуть, что компьютер, даже когда использует 10% своей мощности, потребляет электричества вовсе не в 10 раз меньше, а всего раза в два. Но не будем крохоборствовать. Ведь 99% людей, у которых есть дома компьютер и высокоскоростной интернет, принадлежат к «золотому миллиарду», так что плюс-минус несколько долларов в месяц большой роли не играют.
Итак, соберём всё вместе. 1 гигабайт памяти, полтора ядра на частоте 1.5 — 2 гигагерца, 350 гигов на винте, канал 7 мегабит/сек умножим на пол-миллиарда:
+ 500 петабайт оперативки
+ 750 миллионов ядер
+ 175 000 петабайт дискового пространства
+ 3.5 петабит/сек полосы пропускания
— 300 Тераватт/час электричества (около 0,3% мирового потребления электричества)
— 100 миллиардов долларов в год, из которых 50 мы уже заплатили в момент покупки компьютера
Критически настроенный читатель (а я надеюсь, таких здесь большинство) может потребовать пруфлинки ко всем цифрам в предыдущем абзаце. Я рискнул их не приводить, так как это были бы несколько десятков ссылок на разрозненные куски статистики разной степени достоверности за последние несколько лет, которые сильно засорили бы текст. Для раскрытия темы статьи важен порядок величин, так что особая точность не нужна. Тем не менее, если у кого-то есть готовая достоверная статистика из той же оперы, и она сильно отличается от моих цифр, буду рад её увидеть.
Итак, большая часть этого океана ресурсов остаётся неиспользованной. Как до неё добраться? Можно ли сделать так, чтобы доступность сайта при резком всплеске посещаемости росла, а не падала, как это происходит в файлообменных сетях? Можно ли создать систему, которая позволяла бы мне отдать часть свободных ресурсов своего компьютера интересному стартапу, чтобы помочь ему встать на ноги? Первые шаги в этом направлении уже делаются, но, как и всякие первые шаги, особо успешными их пока не назовёшь. Любые распределённые системы на порядок сложнее централизованных при сопоставимом функционале. Объяснить, что такое гиперссылка на файл, который хранится где-то на сервере, можно даже ребёнку. А вот разобраться, как работает DHT, сможет не каждый взрослый.
Фрагменты мозаики
Самая большая проблема, с которой приходится иметь дело при «размазывании» сайта по неопределённому множеству клиентских компьютеров — динамический контент. Распределённое хранение и раздача статических страниц мало чем отличается от раздачи любых других файлов. Вопрос целостности и подлинности страниц решается с помощью хэшей и цифровых подписей. К сожалению, эпоха статических сайтов на чистом HTML закончилась раньше, чем распределённые сети и протоколы созрели и широко распространились. Единственная ниша, где просто нет других альтернатив — анонимные зашифрованные сети сети вроде FreeNet или GNUnet. В них создать нормальный веб-сервер с постоянным адресом невозможно по определению. «Сайты» в этих сетях как раз состоят из наборов статических страниц или сообщений, объединённых в форумы. Кроме того, чем больше трафик шифруется и анонимизируется, тем быстрее полоса пропускания таких сетей стремится к нулю, а время отклика — к бесконечности. Большинство людей не готово терпеть такие неудобства ради анонимности и приватности. Подобные сети остаются уделом гиков, политических диссидентов и всякой нечисти вроде педофилов. Когда я стал писать о приватности, абзац настолько разросся и так сильно выпирал из окружающего текста, что я оформил его отдельным топиком. Так что вот вам лирическое отступление.
Чуть ближе к нашей теме проект Osiris. Он сосредоточен именно на создании распределённых сайтов — «порталов», а не на анонимном файлообмене и сообщениях. Хотя анонимности там тоже хоть отбавляй. Чтобы безответственные анонимусы не загаживали порталы флудом и спамом, используется система учёта репутации, которая может работать в «монархическом» режиме — репутацию присваивает владелец портала, и в «анархическом» — в создании репутации участвуют все посетители. Проект относительно молодой, авторы — итальянцы, большая часть документации пока не переведена даже на английский (не говоря уже о русском), так что статья в Википедии, пожалуй, будет посодержательней, чем официальный сайт.
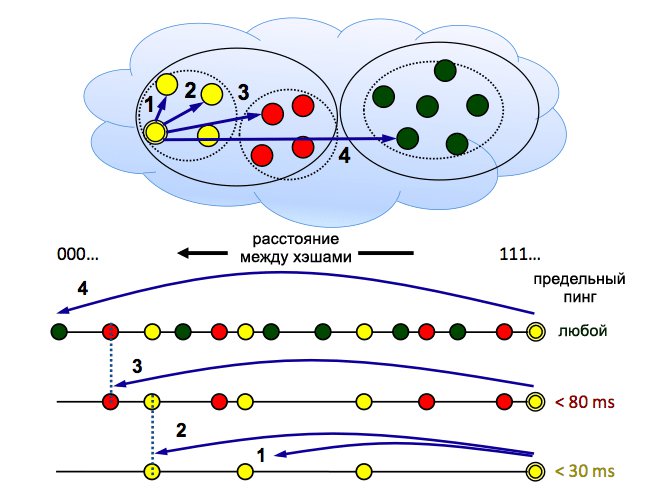
Гораздо интереснее системы распределённого кэширования и CDN. О Coral CDN слышали многие. Хотя распределённая сеть Coral базируется на серверах PlanetLab, а не на пользовательских компьютерах, её архитектура представляет большой интерес. Одна из главных фишек сети — помощь маленьким сайтам в моменты пиковой нагрузки под слэшдот- или хабраэффектом. Достаточно дописать справа от URL ресурса «волшебные слова» .nyud.net, и весь трафик пойдёт через Coral. При обращении по ссылке сеть ищет нужный ресурс по хэшу запроса, используя модифицированный вариант DHT — sloppy DHT. Слово «sloppy» означает, что информация о пирах «размывается» по нескольким узлам с близким значением хэша, снижая нагрузку на самый близкий к хэшу ресурса узел (если вы ничего не поняли в последнем предложении, то вот здесь понятным языком изложены основы архитектуры Distributed Hash Table). Кроме того, Coral разбивает таблицу хэшей на кластеры, в зависимости от пинга между узлами, чтобы уменьшить время отклика — ведь если при скачивании фильма можно и подождать минутку, пока DHT найдёт достаточно пиров, то при загрузке страницы лишние несколько секунд сильно раздражают.
Ещё два маленьких шажка в сторону распределённых веб-сайтов — BitTorrent DNA и FireCoral. DNA работает на основе BitTorrent, и предназначен для раздачи тяжёлого контента. Он требует установки на клиентскую машину загрузчика, который собственно качает файлы или видео. Принцип действия загрузчика мало чем отличается от обычной торрентокачалки, за исключением того, что потоковое видео всегда грузится последовательно, чтобы можно было начинать смотреть, не дожидаясь полной загрузки. Загруженные файлы хранятся в кэше и раздаются другим клиентам. Мне уже пару раз попадались DNA-загрузчики, когда я качал какие-то драйвера. Работает это всё пока только под Windows.
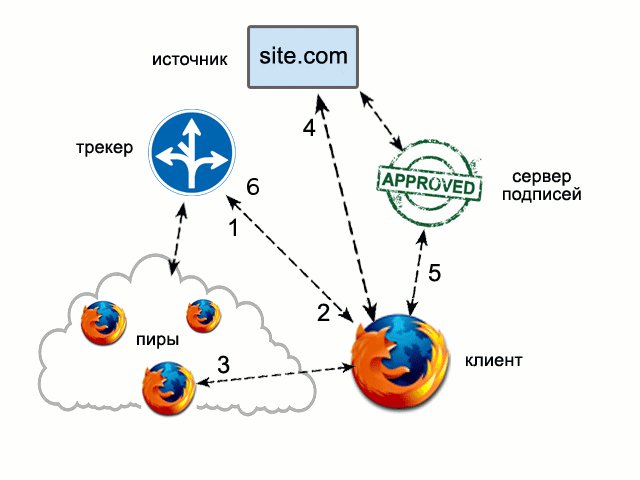
FireCoral — это младший родственник Coral CDN, дополнение для FireFox, которое должно работать на базе клиентских компьютеров, а не серверов PlanetLab. Толком погонять его мне не удалось, так как на момент написания статьи скачали это дополнение всего 1404 человека. А использовал его аж 1 человек за последние сутки. Вот подробное описание архитектуры FireCoral. В двух словах: FireCoral перехватывает HTTP-запросы, и, если в кэше браузера нет ничего подходящего, обращается к трекеру (1). Трекер либо сообщает(2) клиенту адреса пиров, у которых в кэше есть нужный файл (3), либо отправляет его на сервер-источник, если запрос ещё никто не кэшировал, или версия в кэше просрочена (4). Подлинность всего, что FireCoral скачал с пиров, удостоверяется цифровой подписью, которую предоставляет доверенный сервер подписей (5). Завершив обработку запроса, FireCoral сообщает трекеру, что теперь у него тоже есть копия (6).
Недостатки существующих систем распределённого кэширования очевидны и довольно существенны. Кэширование происходит без участия (более того, без ведома!) сервера. Это затрудняет сбор статистики посещений, контроль над распространением контента и создаёт потенциальные угрозы безопасности как для сервера, так и для клиента. С точки зрения сайта, подобная P2P-сеть очень похожа на открытый прокси-сервер. Справиться с этими трудностями возможно, только если сайт знает о существовании распределённого кэша и контролирует его. В терминах архитектуры FireCoral это значит, что сервер-источник одновременно служит и трекером и доверенным сервером подписей. Если сейчас веб-сервер самостоятельно делает всю работу по обслуживанию клиентов, то в такой архитектуре ему остаётся только роль «надсмотрщика», который управляет пирами, делающими всю чёрную работу.
Ещё больше возможностей появляется, если не только веб-сервер сотрудничает с P2P-сетью, но и клиенты в явной форме помогают конкретному сайту. То есть не только делятся контентом, который они скачали для себя, но позволяют сайту хранить на своём диске информацию, которая конкретно им не нужна, например, редко используемый контент. Или помогают производить сложные вычисления.
С хранением проще всего. Криптография позволяет хранить любые данные в облаке или на сервере, не доверяя ему. Так работает, например, Wuala — один из конкурентов Dropbox. Wuala позволяет увеличивать доступное место для хранения своих файлов не только за счёт своих датацентров, но и за счёт дискового пространства пользователя. То есть программа-клиент использует мой компьютер, как часть облачного хранилища. Я расплачиваюсь за хранение своих файлов в облаке не деньгами, а ресурсами своего диска и интернет-соединения. Все файлы шифруются, так что я не знаю, кто и что хранит на моём винте, более того, файлы хранятся не целиком, а по частям, это фактически распределённая файловая система. То есть шансы, что кто-то соберёт по кусочкам и расшифрует мои файлы исчезающе малы.
К сожалению, Wuala не особо продвигает эту фишку, но их можно понять. Громко и внятно предлагать пользователям увеличивать доступное место бесплатно — значит пилить сук, на котором сидишь. Чтобы продвигать сервис синхронизации и хранения в P2P-облаке, нужна другая бизнес-модель. Например, биржа ресурсов — столько-то терабайт спроса на ещё сколько-то предложения. Нужно включить в это уравнение деньги, например, у меня есть 100 гигабайт свободного места, а для того чтобы компенсировать файлы, которые я храню в облаке, нужно 150. Вместо недостающих 50 гигабайт я расплачиваюсь деньгами. Сервис берёт маленькую комиссию. А если наберётся достаточно много пользователей, и баланс спроса и предложения позволит, то можно будет продавать ресурсы на сторону.
Возвращаясь к распределённым веб-серверам, можно представить систему вроде Flattr, но вместо денег в ней будут распределяться гигабайты и мегабиты, а оцениваться будут не конкретные куски контента, а сайты целиком.
Гораздо хуже обстоят дела с вычислениями. Мы не можем просто так позволить неизвестно кому манипулировать нашими данными на своей машине. Если шифрование позволяет хранить любую инфромацию реклама где попало, не опасаясь за её конфиденциальность, а подписи и сертификаты дают возможность кому попало распространять нашу информацию, исключая возможность подделки, то обрабатывать и модифицировать эту информацию в зашифрованном и подписанном виде невозможно. Нам придётся в какой-то степени доверять узлам распределённой сети. И придётся тратить ресурсы на проверку узлов на предмет случайной или преднамеренной порчи данных.
Вопрос доверия невозможно решить «в лоб» на клиентском компьютере. Обфускация кода клиента, всяческие античит-мониторы — это громоздкий неудобный костыль. Создатели всяких MMORPG воюют с этим постоянно. Рано или поздно всё можно пропатчить. Вернее, почти всё. Есть такая штука — trusted computing. Добро пожаловать в прекрасный новый мир! Кошмар Ричарда Столлмана, мечта Большого Брата — в каждом компьютере стоит чип, который следит за тем, чтобы мы делали только то, что нам положено, когда положено и как положено. Такой вариант решения гораздо хуже самой проблемы.
Реально работает другой метод. Он давно и успешно используется матушкой-природой. Это иммунитет. Любой организм весьма эффективно обнаруживает враждебные или неправильно работающие клетки и уничтожает их. Подобные системы придуманы и для P2P-сетей.
Например, платформа для распределённых вычислений BOINC, на которой базируются проекты «что-нибудь@home». В ней используется метод консенсуса. Один и тот же фрагмент данных отдаётся на вычисление нескольким участникам, а результат заносится в базу только если все вернули одинаковые данные. Если нет, значит кто-то ошибся или сжульничал. Исправить ошибку можно двумя основными способами — если есть доверенный сервер, вычисление спорной порции данных поручается ему, и все, кто дал другой ответ, идут лесом. Если сеть полностью распределённая и одноранговая, то правильным считается ответ, который дало большинство участников, этот способ известен под названием «quorum consensus». Кроме того, возможен промежуточный вариант — для каждого узла по результатом предыдущей работы вычисляется репутация. Ответ узлов с большей репутацией имеет больший вес при разрешении конфликта.
Как это всё применимо к распределённым веб-сайтам? Любые данные, которые отдаёт веб-сервер можно разделить на три группы:
Данные, раскрытие и несанкционированное изменение которых абсолютно недопустимо — пароли, номера кредитных карт, личные сообщения и файлы. Их можно хранить и передавать только в зашифрованном виде.
Данные, которые могут видеть все, но их произвольное изменение недопустимо.
Например, JavaScript на странице. Такие данные должны быть в обязательном порядке проверены и подписаны доверенным источником.
Данные, несанкционированный просмотр которых нежелателен, но не является катастрофой. Например, содержимое закрытых блогов здесь, на Хабре.
Данные, несанкционированное изменение которых может быть легко исправлено впоследствии. Например, статья в Википедии, которую починить гораздо легче, чем испортить. Ради большей децентрализации можно допустить проверку и публикацию таких данных без участия доверенного сервера, методом quorum consensus.
Итак, сегодня уже существует принципиальная возможность дотянуться до «тёмной материи» ресурсов глобальной сети. Однако действительно массовым пока стал только файлообмен. Наверное, дело в том, что полноценная и безопасная работа P2P-сайта требует серьёзного пересмотра основ сайтостроения — очень сильно меняется архитектура, подход к контролю доступа, возникают новые риски. Ну и конечно, вечная проблема курицы и яйца. Распределённых сайтов нет, потому что нет инфраструктуры, инфраструктуры нет, потому что нет распределённых сайтов.
Сейчас самая перспективная, на мой взгляд, попытка разорвать этот порочный круг со стороны рспределенных сайтов, а не инфраструктуры— проект Diaspora. Хотя пока что разработка в стадии альфа-версии, им удалось привлечь к себе внимание широкой публики и собрать кучу денег на kickstarter.com Даже Марк Цукерберг внёс свою лепту в финансирование проекта. Создатели Диаспоры не замахиваются на решение проблемы распределённого хостинга в общем виде, а делают социальную сеть, которая по своей природе хорошо ложится в архитектуру P2P. Главный «пряник», которым они привлекают людей — полный контроль над своими данными. Диаспора — не единственный проект такого рода, есть ещё GNUsocial, Appleseed, Crabgrass, но никому из них не удалось стать настолько популярным.
Диаспора — это веб-приложение на Ruby on Rails. Чтобы поднять свой сервер Диаспоры, нужен Linux или MacOS X, поверх них thin и nginx (тут возможны варианты). До Windows пока руки авторов не дошли. Создание простого установщика для не-гиков — в планах на будущее. В архитектуре Диаспоры используется ботаническая терминология: сервер — это «стручок» (pod), аккаунт пользователя — «зерно» (seed). Каждый стручок может содержать одно или несколько зёрен. Пост — фотография, сообщение и т. д. — может принадлежать одному или нескольким «аспектам». Аспект — группа пользователей, например «родственники», «работа», «друзья». Диаспора использует криптографический контроль доступа. Что это такое?
Привычные модели контроля доступа, такие, как ACL или RBAC, целиком и полностью полагаются на доверенный сервер, который решает, кого пускать, а кого нет. Как сторожевая собака. Если наши данные хранятся где попало, мы уже не можем рассчитывать, что на каждом сервере есть достаточно злая собака, которая добросовестно охраняет секреты. Её там может вообще не быть, или собака может путать своих и чужих. В таких условиях нам придётся запирать каждый кусочек информации на замок, чтобы только тот, у кого есть ключ, мог получить доступ. Это и есть криптографический контроль. Мы управляем доступом к любой информации, шифруя её, и раздавая ключи тем, кому считаем нужным.
Самая большая проблема криптографического контроля — практическая невозможность надёжно отобрать доступ у того, кто раньше этот доступ имел. Для этого придётся перешифровать всю информацию другим ключом, и распространить этот ключ среди всех членов группы. Даже если нам удастся сделать это довольно оперативно, мы не можем рассчитывать на то, что удалённый из группы пользователь не сохранил расшифрованную информацию, когда ещё имел подходящий ключ. Впрочем, мы уже привыкли, что всё опубликованное в интернете остаётся там навсегда.
То что мы не можем сделать однажды опубликованную информацию недоступной на 100%, не означает, что не стоит даже пытаться. 99% — это тоже неплохо. Однако, перешифрование и раздача новых ключей — весьма ресурсоёмкий и медленный процесс. Если число членов группы, из которой мы хотим исключить кого-то, не очень велико, и нас устраивает 99% гарантия успешного «отлучения», то мы таки перешифруем всё и раздадим новые ключи. Если же группа очень велика, и информации много — то овчинка не стоит выделки, и можно ограничиться только заменой ключей, так что исключённый пользователь сохранит доступ к старой информации, но не к новой.
Как конкретно выглядит процесс криптографического управления доступом? Пусть нам надо дать доступ группе из N пользователей. Информация шифруется случайным ключом симметричным алгоритмом. Этот ключ, в свою очередь, шифруется открытыми ключами каждого из N. Зашифрованная информация + N по-разному зашифрованных экземпляров случайного ключа упаковываются, подписываются и раздаются членам группы. Чтобы исключить кого-то из группы, надо повторить весь процесс с N-1 ключами, и пометить старый экземпляр зашифрованного файла для удаления на всех пирах. Или, если мы можем смириться, с тем, что старая информация останется доступной, достаточно просто в дальнейшем шифровать случайный ключ к новой информации N-1 ключами пользователей. Если же мы наоборот, хотим дать доступ новому члену группы, нам достаточно прислать ему ключи от всех старых файлов.
Это самый прямолинейный способ реализации криптографического контроля. Чтобы уменьшить количество распространяемых ключей, можно использовать разнообразные иерархические системы производных групповых ключей. Вместо N можно обойтись O(logN) ключами, но это сильно усложняет схему. В пределе, когда N — очень большое число, а возможность замены ключей отсутствует в принципе, получается такой монстр, как AACS — основа DRM. Оставляя за скобками юридические, социальные и этические аспекты DRM, устройство AACS — штука невероятно увлекательная. Subset difference tree system чем-то похожа на квантовую механику — если вы думаете, что понимаете её, значит вы её не понимаете. По крайней мере я прошёл сквозь три или четыре уровня ложного понимания, пока разбирался с её работой (может их и больше, но к сожалению, у меня не настолько много свободного времени, чтобы продолжать копать глубже). Подробнее о криптографическом контроле доступа можно почитать вот здесь, см. главу 2.3 в документе по ссылке, только осторожно, там толстый PDF!.
Фантазии и домыслы
Что нужно, чтобы распределённые веб-сайты стали обычным делом?
Во-первых, инфраструктура. Программа-клиент, вроде uTorrent, или плагин к браузеру, вроде FireCoral, или поддержка функций веб-сервера браузером, вроде Opera Unite. Какие функции должна обеспечивать эта инфраструктура?
Неявное автоматическое распределённое кэширование сайтов, которые я посещаю. (Примеры — FireCoral, BitTorrent DNA)
Явное предоставление ресурсов моего компьютера тем сайтам, которые я хочу поддержать. (Примеров пока нет. Единственное, что приходит в голову — недавние события вокруг Wikileaks, когда сочувствующие вручную создали сотни зеркал сайта)
Публикация или хранение в P2P-облаке моих собственных ресурсов. (Примеры — Diaspora, Opera Unite, Wuala)
Во-вторых, архитектура веб-приложения.
Веб-сервер должен стать трекером собственной P2P-сети и центром сертификации.
Реляционные БД подходят плохо. В распределённой среде слишком накладно собирать веб-страницу из маленьких кусочков данных, разбросанных по разным таблицам. Нужны более крупные денормализованные фрагменты, чтобы можно было обойтись всего несколькими простыми запросами. Документ-ориентированные БД и хранилища key-value соответствуют задаче гораздо лучше. Именно документы таких БД, а не целые страницы, лучше всего хранить в распределённом кэше.
Криптографический контроль доступа, и вообще повсеместное обязательное использование криптографии.
Широкое использование модели распространения данных Push on change вместо Pull on demand.
Представим, как мог бы работать, например, Хабрахабр, будь он распределённым. Допустим, что вся инфраструктура уже существует и работает. Заходя на главную, я получаю от сервера только актуальный список пиров, с которых могу скачать собственно страницу, и её хэш. Сама страница тоже не совсем обычна. Если кэшировать её целиком, то из-за часто меняющихся фрагментов, таких, как «Прямой эфир», или числа комментариев под каждым топиком, она будет устаревать практически мгновенно.
Поэтому первым делом качается статический каркас страницы — шапка, подвал, стили и JavaScript, который после загрузки подтянет динамические куски ещё несколькими запросами. Причём сами эти куски тоже сильно отличаются по скорости обновления. Если «Прямой эфир» может обновляться несколько раз в минуту, то «Лучшее за 24 часа» меняется довольно редко.
Собственно, именно так сейчас выглядит правильно организованное кэширование на стороне сервера. Почти любая динамическая страница на 99% состоит из таких вот более-менее статических кусков. Разница в том, что готовая страница будет собираться из этих кусков на стороне клиента, а сами куски будут находится в P2P-сети.
Как будут распространяться обновления данных? Допустим, кто-то написал комментарий к этому топику. При каждом запросе, будь то создание комментария, оценка или просто обновление страницы, клиент обновляет список пиров у себя и у того узла, к которому он обратился. Чем активнее я участвую в обсуждении, тем актуальнее мой список пиров, и тем быстрее я получаю свежую информацию. То есть все обновления распространяются прежде всего локально, в том «рое», который сейчас жужжит вокруг топика. Обновления подписываются хабраюзером, так что подделать или испортить что-либо достаточно трудно. В крайнем случае, если, например, несколько узлов сговорятся и начнут намеренно искажать информацию, безобразие будет длиться недолго — центральный сервер «заглядывает к нам на огонёк» каждые несколько минут, сохраняет свежие комментарии и оценки и проверяет их подлинность и валидность. В эту схему отлично выписывается технология pubsubhubbub (смешнее всего это слово произносят японцы).
В принципе, сайт может временно или постоянно работать вообще без центрального сервера. Он необходим только на этапе первоначального роста сети и формирования ядра аудитории. В дальнейшем сервер просто ускоряет и упрощает работу, и позволяет хозяевам сайта управлять развитием проекта. Если использовать систему учёта репутации, то несколько десятков самых авторитетных узлов могут играть роль трекеров и центров сертификации, поддерживая стабильность сообщества и целостность распределённой БД. Чтобы уничтожить или взять под контроль такую сеть, надо одновременно захватить большинство авторитетных узлов, что гораздо труднее, чем отключить центральный сервер.
Чтобы сделать такой сайт вообще неубиваемым, остаётся придумать децентрализованный аналог DNS. Или можно заменить DNS децентрализованной поисковой системой. Например, когда у Wikileaks один за другим отбирали домены, сайт продолжал висеть первым в выдаче Google, причём вместо доменного имени некоторое время красовался голый IP-адрес. Да и чайники, которые вообще не знают, что такое домен, а просто набирают слово «вконтакте» и щёлкают по первой сверху ссылке — это не фантазия, а реальность. Неизвестно только что труднее создать и внедрить — децентрализованную DNS, или децентрализованный Google?
Ну и напоследок, ещё одна фантастическая возможность полностью распределённой архитектуры — размножение делением. Любой децентрализованный сайт реклама технически не очень сложно «форкнуть», если в нём образуется достаточно сплочённая подгруппа пользователей. Со временем на месте одного сайта может вырасти целое дерево. Заключение
Кому-то этот топик может показаться слишком уж утопичным. Большая часть технологий ещё выглядит довольно сыро и ненадёжно. Но! Вернитесь к цифрам в самом верху. Если есть хоть какой-то шанс дотянуться до всех этих петабайтов, которые сейчас простаивают, разве не стоит хотя бы попытаться? Ведь это будет революция не хуже массового файлообмена и облачных вычислений! Изменения уже витают в воздухе. Базы данных и доступ к файловой системе переползают в браузеры, JavaScript лезет на сервера, NoSQL СУБД набирают обороты, стирается разница между скоростью локальной сети и интернета, очередной проект децентрализованной социальной сети собирает 200 000 долларов без единой строчки кода, только потому, что людям очень хочется в него поверить. Может время уже пришло?




 Иногда я открываю окно торрент-клиента и просто смотрю, как он раздаёт файлы… Это завораживает даже больше, чем дефрагментация или гейзеры и вулканы в трёхлитровой банке с домашним квасом. Ведь я помогаю множеству незнакомых мне людей качать нужные им файлы. Мой домашний компьютер — маленький сервер, ресурсами которого я делюсь со всем интернетом. Наверное, похожие чувства побуждают тысячи добровольцев по всему миру участвовать в проектах вроде folding@home.
Иногда я открываю окно торрент-клиента и просто смотрю, как он раздаёт файлы… Это завораживает даже больше, чем дефрагментация или гейзеры и вулканы в трёхлитровой банке с домашним квасом. Ведь я помогаю множеству незнакомых мне людей качать нужные им файлы. Мой домашний компьютер — маленький сервер, ресурсами которого я делюсь со всем интернетом. Наверное, похожие чувства побуждают тысячи добровольцев по всему миру участвовать в проектах вроде folding@home.